

Data is samen met algoritmes de bouwsteen voor AI-applicaties. Onze omgang met data is wat ambivalent. In privé situaties zien we dat mensen geen moeite hebben applicaties te gebruiken die data tevens voor andere doeleinden gebruiken. In een organisatorische setting zien we juist dat data strikt wordt beschermd. Geen onlogische gedachte: data vertegenwoordigt waarde of het is niet toegestaan om data beschikbaar te maken vanwege privacywetgeving. Hiermee blijft waardevolle data in silo’s en kunnen zeer zinvolle AI-applicaties niet of niet makkelijk worden gerealiseerd.
Ontwerp datadeelinfrastructuur
In het in maart 2020 verschenen rapport ‘Verantwoord data delen’ is de behoefte aan een datadeelinfrastructuur omschreven. Hierin is een voorzet gemaakt hoe deze infrastructuur eruit zou kunnen zien om AI in Nederland te stimuleren.
Goed nieuws: Er zijn methoden en technieken beschikbaar waarbij de eigenaar van de data controle houdt over de data. Het is ook mogelijk dat data niet gedeeld hoeft te worden, maar dat dit beperkt wordt tot de uitkomsten van een langs de databronnen “reizend” algoritme. Met dit soort oplossingen kunnen AI-applicaties van meer en betere informatie worden voorzien. Om dit aan te tonen is er samen met de toepassingsgebieden Gezondheid en Zorg, Publieke Diensten, en Energie en Duurzaamheid een aantal technische ‘Proof of concepts’ (PoCs) uitgevoerd waarbij zogenaamde ‘ecosystems of trust’ in de praktijk zijn opgezet.
Proof of concept Gezondheid en zorg
We gaan op deze pagina nader in op de uitwerking van het proof of concept in de gezondheidszorg. Aan de hand van twee use cases, te weten het analyseren van foto’s en labuitslagen gericht op COVID-19, is aangetoond welke oplossingen er mogelijk zijn voor verantwoord data delen in de praktijk. Deze samenwerking is tot stand gekomen met deelnemers uit verschillende organisaties waaronder het EMC, LUMC, Health RI, GO-FAIR, UT, TNO en de werkgroepen Gezondheid en Zorg en Data Delen van de NL AIC.
Ecosysteem
Privacy en vertrouwen zijn cruciale uitgangspunten om te adresseren in de generieke datadeelinfrastructuur. Organisaties, mensen (rollen), technologie (hardware/software) en AI-algoritmen dienen ten alle tijden te kunnen worden geïdentificeerd en geauthentiseerd.
Meerdere typen data deel methodieken kunnen worden ingezet voor het voeden van AI-algoritmen . In de basis kan de keuze gemaakt worden dat data naar het algoritme (D2A) wordt gestuurd of dat het algoritme naar de data (A2D) “reist”. In beide gevallen is het cruciaal dat het algoritme wordt vertrouwd door iedereen in het ecosysteem. In deze proof of concept zijn beide varianten (A2D en D2A) toegepast. Het A2D algoritme staat in de gezondheidszorg ook bekend als de Personal Health Train.
Vanuit de coalitie wordt tevens het FAIR-principe ondersteund voor de beschrijving van beschikbare data, zodat ‘Machine2Machine’ communicatie mogelijk wordt gemaakt. Datasets en services zijn vindbaar (Findable), toegankelijk (Accessible), uitwisselbaar (Interoperable) en herbruikbaar (Reusable). Naast de FAIR-principes passen we de refentiearchitectuur toe van IDS toe. Hierbij is het mogelijk om per organisatie, gebruiker, algoritme aan te geven welke data mag worden gebruikt en met welke reden. We lichten de uitwerking hiervan in onderstaande tekst nader toe.

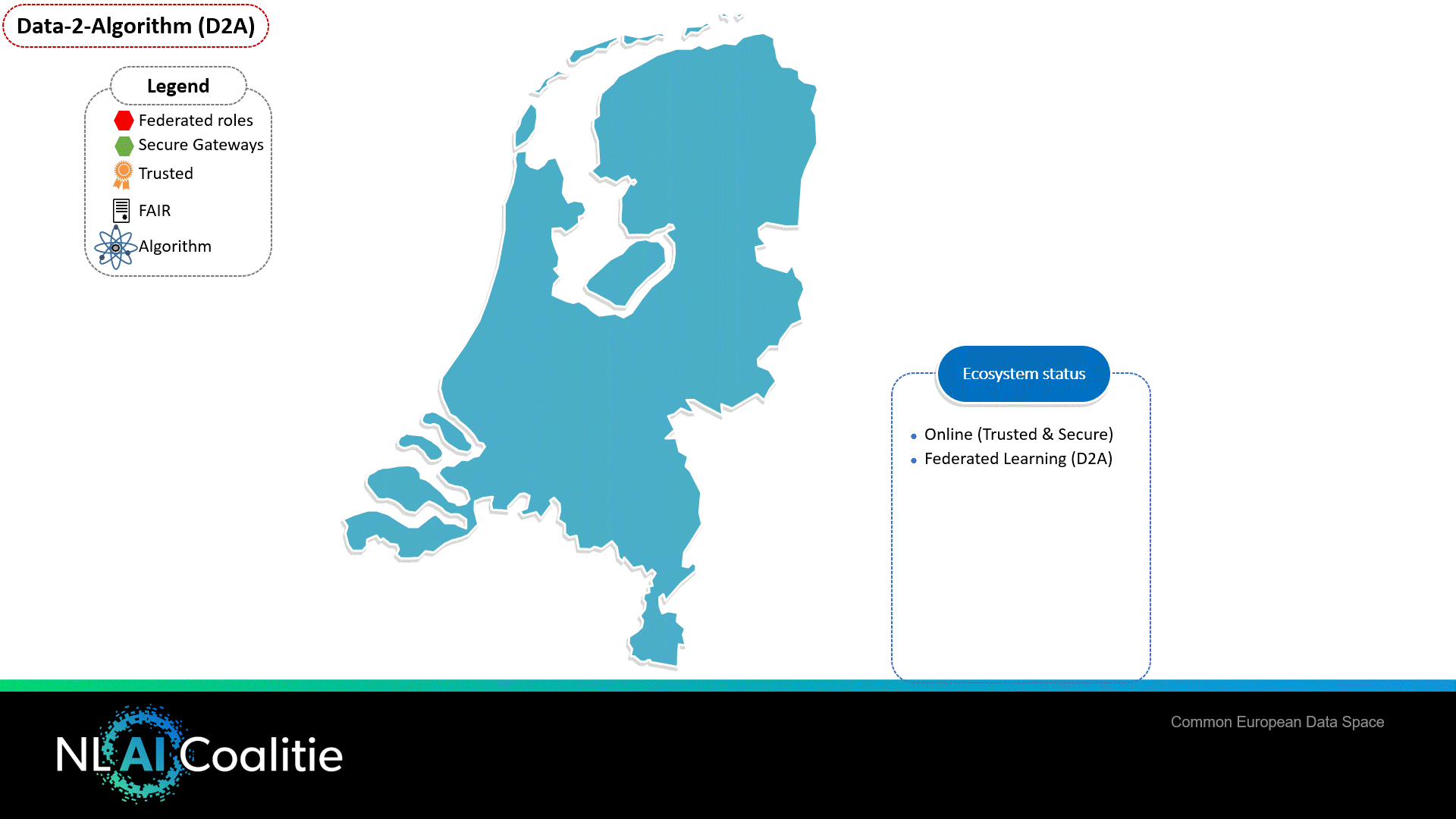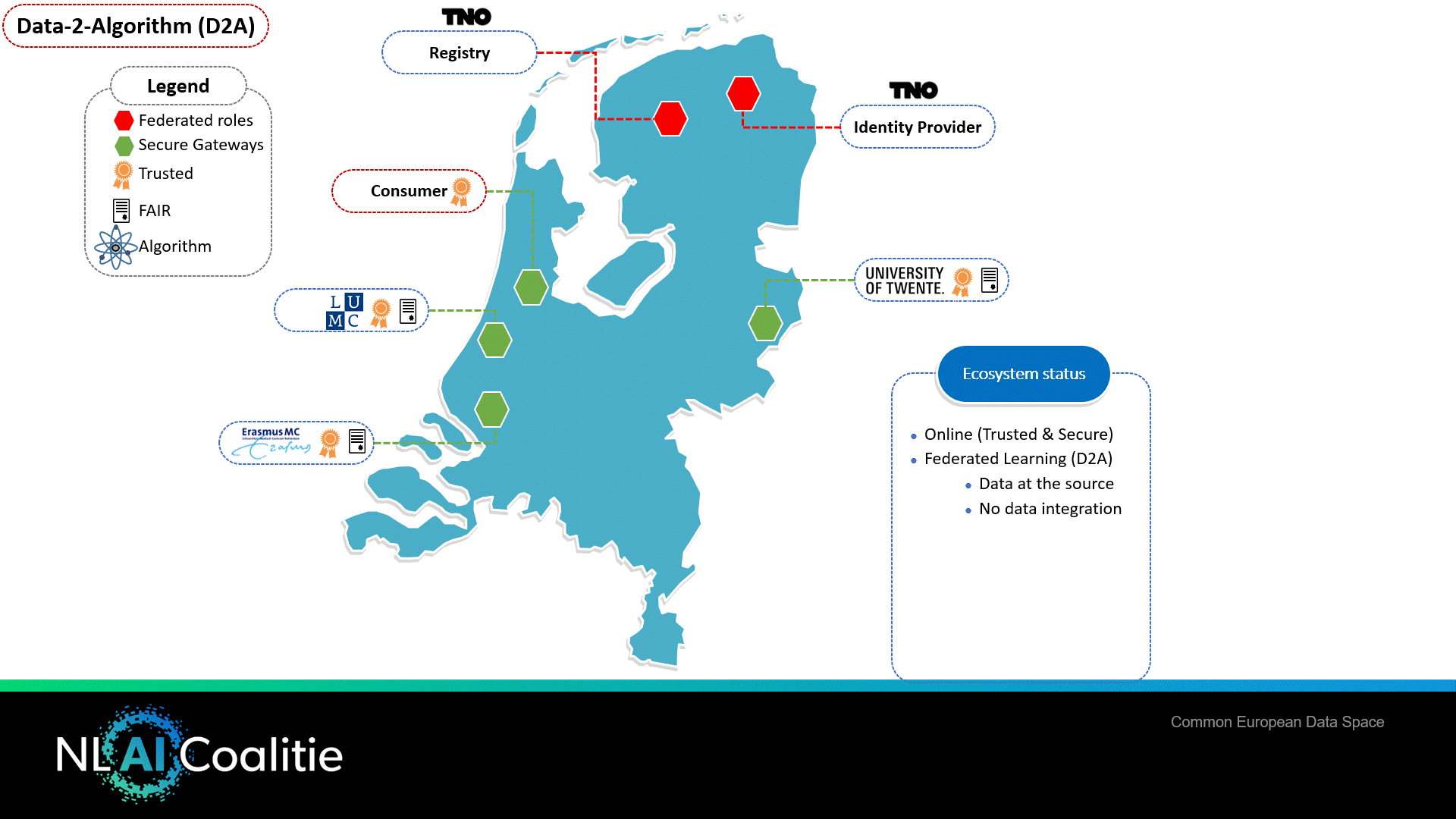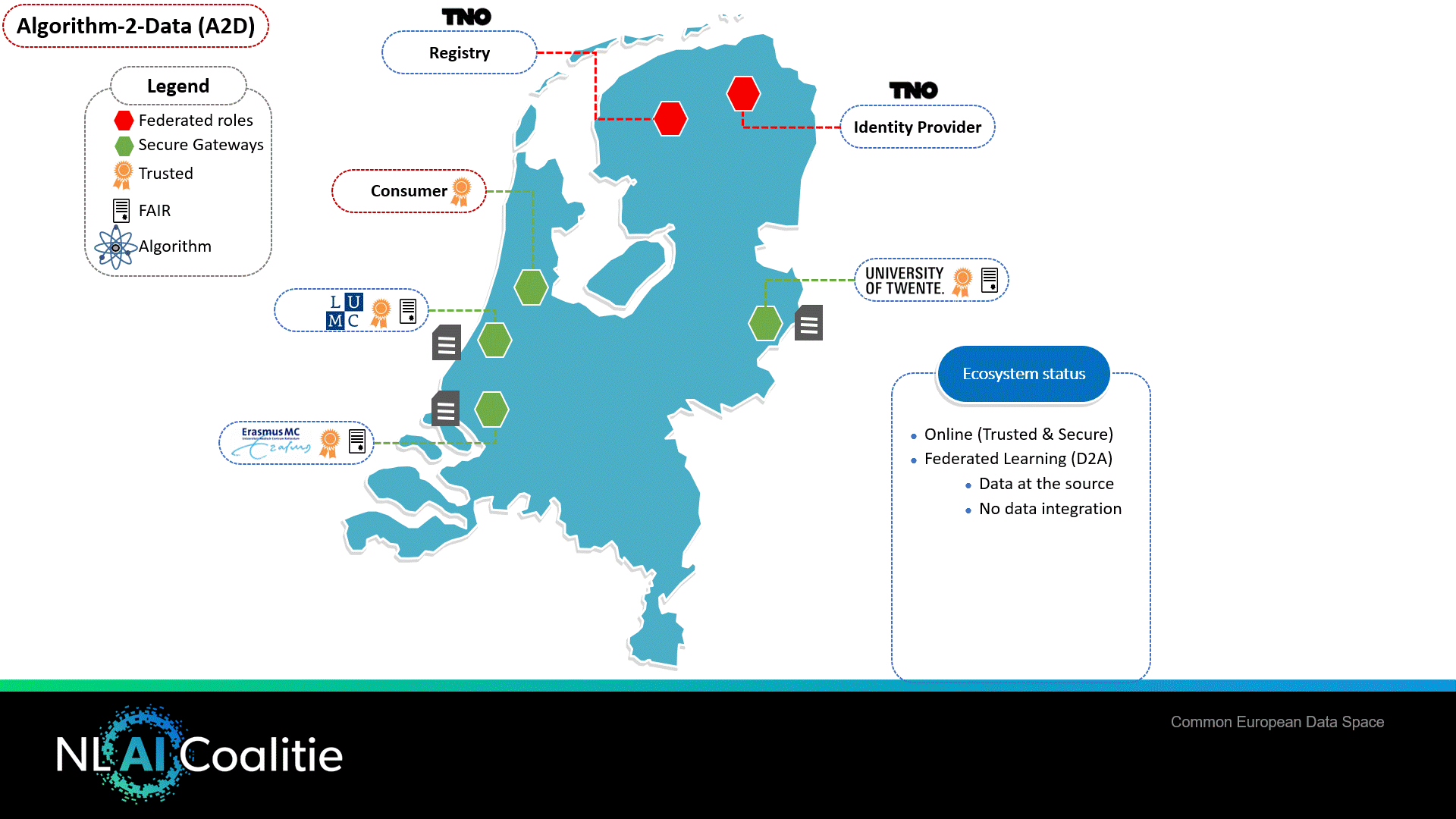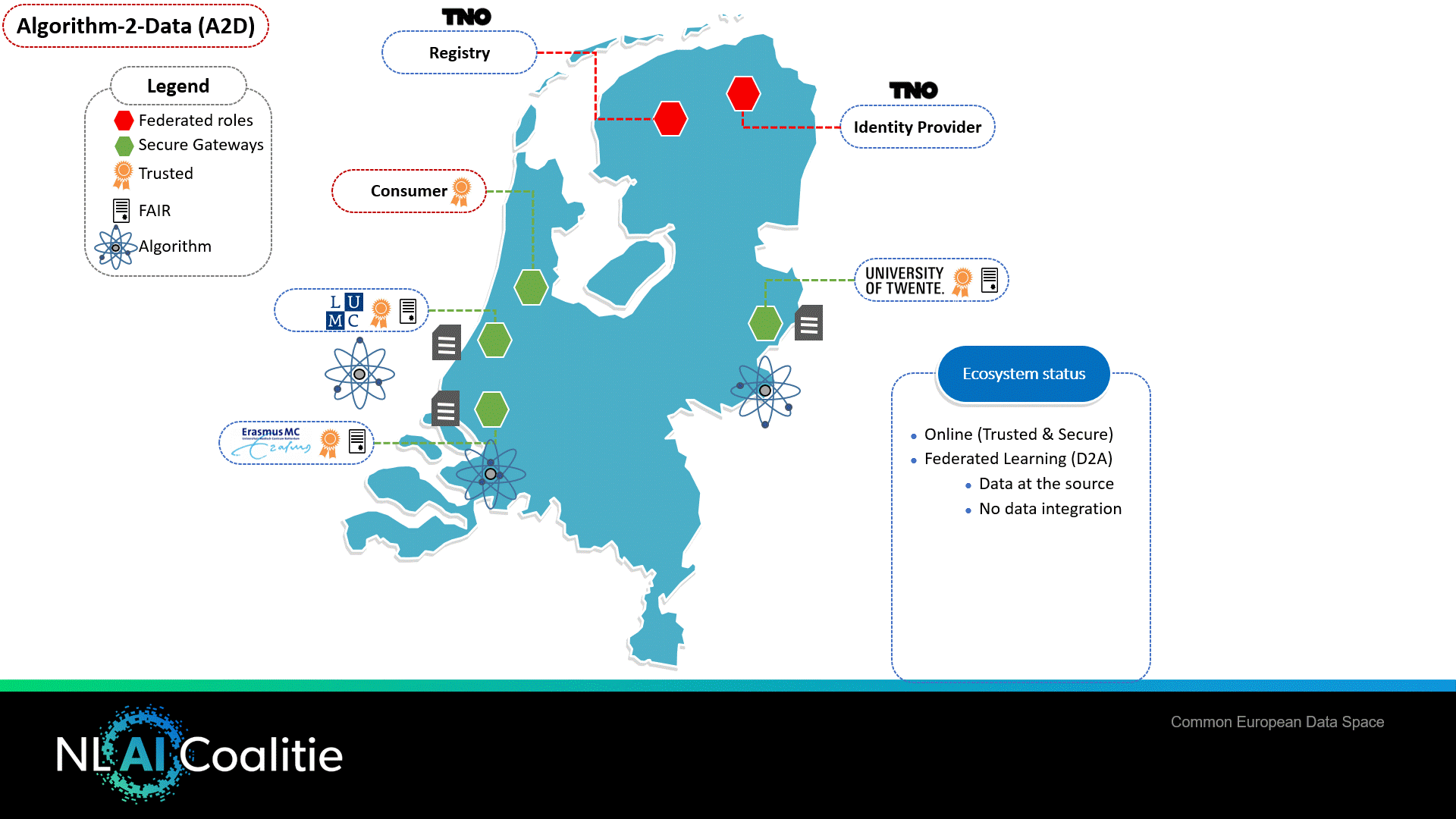
Figuur 1 Datadeelinfrastructuur
International Data Spaces (IDS)
Figuur 1 geeft de generieke data deelinfrastructuur weer die gebaseerd is op internationale standaarden van IDS. In deze case zijn er drie organisaties die willen samenwerken (LUMC, ErasmusMC & Universiteit Twente). Het ecosysteem dient te worden geinitialiseerd, waarbij een aantal generieke rollen benodigd is, namelijk:
- De Identity Provider: geeft digitale certificaten aan deelnemende organisaties om een “trusted ecosystem” te waarborgen.
- Het Registry: elke organisatie dient zich te registeren binnen het ecosysteem (publiceren van datadiensten, conform FAIR).
A. Een deelnemende organisatie installeert een ‘secure gateway’.
B. Een deelnemende organisatie vraagt een digitaal certificaat aan ten behoeve van identificatie en stelt dit certificaat in op haar secure gateway.
C. De organisatie registreert zich in het ecosysteem:- Krijgt een uniek publiek identificatienummer toegewezen
- Registreert op metaniveau welk soort data/service beschikbaar is
Andere organisaties in het netwerk kunnen via het register (vergelijkbaar met een gele gids functie) zien welke organisaties beschikbaar zijn. Zij zoeken op metaniveau naar services/datasets, nemen indien gewenst services af en maken onderling afspraken over datadeling (access & usage constraints). Met behulp van IDS is het door middel van identificatie, authenticatie en autorisatie mogelijk om op het niveau van organisatie, rol, service en dataset te standaardiseren (technisch en governance).

Figuur 2 VODAN – Data naar het algoritme
Virus Outbreak Data Network (VODAN) – Data naar het Algoritme (D2A)
Het datanetwerk bestaat uit meerdere databronnen op verschillende locaties m.b.t. COVID-19 specifieke data. Een semantisch datamodel is beschikbaar gemaakt door GO FAIR (als onderdeel van de financiering van ZonMW en Philips Foundation voor het VODAN-project).
Figuur 2 geeft weer hoe een onderzoeker (data consumer) data opvraagt van meerdere FAIR datastations, waarbij de organisaties zijn geïdentificeerd en geauthentiseerd. Hierdoor is het mogelijk om op het niveau van informatie-elementen autorisatie toe te passen. Er wordt gebruikgemaakt van een semantisch model en het International Data Space rollen model zodat partijen onderling dezelfde taal spreken. Alle acties en/of bewerkingen zijn technische traceerbaar & controleerbaar, waardoor (data)soevereiniteit wordt gewaarborgd.
Het voordeel van deze oplossing is dat er met één druk op de knop een organisatie kan aansluiten bij het netwerk, omdat er één semantische taal wordt gesproken. Er is tevens een gestandaardiseerde manier vastgesteld om organisaties te kunnen vertrouwen gedurende de periode dat er transacties plaatsvinden. Dat betekent dat het eenvoudiger wordt om bertrouwbare dataconnecties te realiseren. Implementatiekosten dalen en vendor lock-in wordt voorkomen.
Figuur 3 Algoritme naar de data
Federated Learning – Algoritme naar de Data (A2D)
Het proof of concept van Gezondheid & Zorg PoC ondersteunt tevens een tweede belangrijke variant van AI, namelijk het versturen van het algoritme naar de data (A2D). Een veel voorkomende vorm voor data delen in AI is Federated Learning (FL). Dit is een gedistribueerde Machine Learning-benadering die tegemoet komt aan de noodzaak om privacygevoelige gegevens niet via het netwerk te delen.
Bij FL zijn er meerdere dataproviders in het netwerk die elk hun eigen set gegevens beheren. De dataconsument (en tevens de leverancier van het FL-algoritme) initieert het proces en treedt op als de orchestrator in het leerproces. FL werkt op hoofdlijnen als volgt:
- Alle dataproviders voeren hetzelfde ML-algoritme uit met behulp van het eigen ML-model op hun eigen dataset, die alleen informatie bevat over de gegevens van de patiënten in de eigen organisatie.
- Het individueel getrainde model wordt door de data providers naar de orkestrerende server gestuurd.
- De orchestrator combineert de modellen van alle individuele dataproviders in één model.
- De orchestrator stuurt het bijgewerkte model terug naar de gegevensproviders.
- Stap 1 tot en met 4 worden herhaald totdat het trainingsalgoritme is voltooid.
Het resultaat is een algoritme dat op meer data getraind is en daarmee statistisch betrouwbaarder wordt, aannemende dat de dataproviders goede kwaliteit data kunnen leveren.
Conclusie: AI heeft een generieke datadeelinfrastructuur nodig
Uit de resultaten blijkt dat het technisch mogelijk is om een infrastructuur voor datadeling op te zetten, die gebaseerd is op internationale standaarden (in overeenstemming met de FAIR richtlijnen en IDS). Er is tevens aangetoond dat data niet fysiek naar andere organisaties hoeft te worden gestuurd om AI succesvol toe te passen (federatieve data-architectuur). Indien wel data wordt gedeeld, is het mogelijk dat de eigenaar van de data via afspraken over de autorisatie controle houdt over het gebruik van zijn of haar data.
De toepassing van generieke standaarden maakt het mogelijk om in allerlei omgevingen en zelfs tussen toepassingsgebieden data te delen. Indien gewenst kan er datadeling over meerdere ecosystemen heen gerealiseerd worden (system of systems-gedachte). Datasoevereiniteit is gewaarborgd by design in deze architectuur evenals de traceerbaarheid van de gemaakte transacties. Alle organisaties in het ecosysteem zijn gecertificeerd en mede daarmee zogenaamde ‘trusted’ organisaties.
Deze aanpak van een generieke infrastructuur voor datadeling kent diverse voordelen:
- Identificatie, Authenticatie en Autorisatie zijn gestandaardiseerd (via secure & trusted handshakes).
- Semantieke modellen conform FAIR-principes zijn een goede basis.
- Meerdere typen AI-algoritmen kunnen worden ondersteund waarbij eisen op het gebied van privacy in acht worden genomen.
Opschaling tot een grootschalige testomgeving
Bovenstaande uitwerking betreft momenteel afgebakende Proof of Concepts. De komende periode wordt de groep van belanghebbenden uitgebreid om tot een grootschalige testomgeving te komen richting operationele praktijk implementaties. Zo kan ervaring worden opgedaan om versnelling in AI-implementaties te realiseren. Om de ontwikkeling van AI-innovaties te stimuleren, stelt de Nederlandse AI Coalitie de proof of concept software vrij beschikbaar via GitLab.





